Contributed by Anand Umashankar, Tech Lead, Sharper Shape
Have you ever heard of Espoo, Finland? If you’re not Finnish, maybe not. It is a city of 314,000 inhabitants in the south of Finland, perhaps most famous internationally for Aalto University.
But, if you’re a researcher working in deep learning based on 3D LiDAR models, you may be about to become intimately acquainted with the city – or at least with 10km2 of it.
That’s because of the recent publication of Extended Classification of LiDAR for AI Recognition dataset – aka ECLAIR.
ECLAIR filling
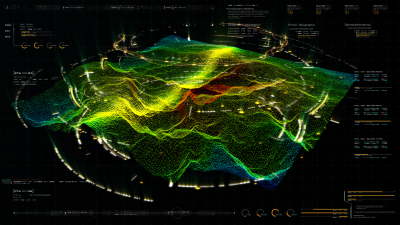
ECLAIR is an open-source dataset covering a contiguous area of more than 10km2 of Espoo, Finland, consisting of more than half a billion points captured by long-range high-accuracy LiDAR.
Captured aerially by helicopter using Heliscope, data capture focused on electrical transmission lines, which consequently shape the point cloud network. The dataset has then been augmented with point-wise semantic annotations. In short, ECLAIR is a high-fidelity, data rich digital twin of the powerline network in the target area.
There are never enough ECLAIRs
Anyone with even a passing interest in artificial intelligence (AI) will have marveled at the extent and speed of developments in recent years, with the likes of Chat GPT and LaMDA becoming hot business buzzwords, if not household names.
However, these advances have largely been limited to the field of large language models (LLM) and their success has been in no small part due to the wide variety of extensive datasets available to the research community to train with.
When it comes to 3D visual and spatial data – specifically 3D LiDAR – the same extensive datasets have not been available. For example, the CommonCrawl dataset used by the LLaMA model (Meta’s LLM), spans approximately 6 petabytes. By contrast the DALES dataset – which includes aerial LiDAR 40 scenes over a 10km2 area – amounts to just a few gigabytes.
This is not to criticise datasets such as DALES, which has been an invaluable tool to the research community, but to point out the disparity between what is available to researchers in the LLM community versus those working with 3D LiDAR. This is understandable to an extent: it is costly and labor intensive to conduct aerial scanning, and even ground-based scanning is costlier than assembling purely language-based datasets. In the future, data collection via unmanned aerial vehicles (UAVs/drones) may help reduce the cost of data acquisition but today the fact remains: there is a paucity of data available compared to other deep learning fields.
For research and innovation to continue and accelerate, more and richer datasets are needed.
Why the world needs more ECLAIRs
Why does this matter? Outdoor 3D scene understanding is essential for many applications in computer vision, from autonomous driving, to robotics, to augmented and virtual reality. At Sharper Shape, we use such data to drive advances in powerline inspection and utility management. Equally, similar approaches could be applied by urban planners developing infrastructure such as roads and bridges, or even to use detailed annotated point clouds of buildings to identify existing structures, understand urban density and plan new developments accordingly.
A step further into the future, it can be imagined that authorities can use such datasets to understand and develop critical infrastructure resilience to natural disasters such as floods and wildfires, or to bolster conservation efforts with a more granular understanding of vegetation and urban green spaces.
Likewise, datasets such as ECLAIR could be integrated with internet of things (IoT) devices and urban management systems to optimize city functions and services – anything from traffic flow to refuse collection. The ‘smart city’ has been a tantalizing concept for some years now, but it is AI trained on large datasets that can make it reality.
Against the backdrop of urban densification and the need to mitigate and adapt to the risks of climate change, there are a wealth of possibilities for deep learning models applied to such aerial 3D LiDAR datasets. These may be even more powerful tools when combined with complementary datasets such as ground-captured 3D LiDAR and satellite aerial imagery.
All these use cases depend on the development of AI tools that can accurately generalize to real-world scenarios. This in turn depends on the availability of large, rich datasets that can be used to experiment with and train innovative deep learning models.
If that seems abstract, think back to June 10, 2001, with the launch of Google Earth. Remember the excitement the program was greeted with, the amazement at being able to explore an accurate model of the whole world with just a standard PC. In theory, 3D LiDAR could enhance that to a fully 3D, richly annotated digital twin of the world, creating a sandbox and toolbox for researchers, developers and explorers alike. Today though, we can start with Espoo, Finland.
The ECLAIR dataset can be found on GitHub here. More information can be found in the paper: ECLAIR: A High-Fidelity Aerial LiDAR Dataset for Semantic Segmentation on the Sharper Shape website.

Anand Umashankar, the Tech Lead for the ML team at Sharper Shape, is a seasoned Machine Learning Engineer specializing in computer vision. His expertise in LiDAR technology and its integration with sparse convolutional networks enables him to ideate smart solutions for analyzing 3D data. He enjoys collaborating with other teams to develop robust systems and create scalable deep learning applications suitable for production environments. With a passion for open-source contributions, he seeks to collaborate and share his knowledge within the community.

.jpg.small.400x400.jpg)